Trying out Buffalo
trying-outI’m trying out a new concept: my “I should check this out” list of tools and technologies has grown quite a bit so I got the idea that I could do short write ups of my experimentation and first impressions to give myself motivation to try these things out. Will see how this turns out, hopefully this will turn out a series :)
Today I’ll be trying out Buffalo - a Go web framework. I believe this one distinguishes itself by focusing on developer productivity - a kind of “Rails for Go”. But apparently it’s mostly some glue and tooling around a bunch of other established libraries. I very much like this approach. And yes, I agree that “just use standard library” is not (always) the right approach. Sometimes you just want to bootstrap a small project quickly.
Let’s see if it delivers on this promise.
Disclaimer this is not intended to be a review or a tutorial, just my first impressions, trying to convey the flavor I experience.
Final code is available on Github if you want to read through anything.
Getting started
I start by working through the docs - Installation.
I need Go, or I need to update it at least (I use NixOS, following commands should work on most Linux distributions if you use Nix package manager.
| |
And some frontend stuff
| |
not bothering with sqlite at this point, I’ll probably use a dockerized Postgres for development.
I’ll install the buffalo tooling using the prebuilt Linux binary.
| |
Does it work?
| |
I get some output. Yay!
Moving on to Generating a new project
| |
Command suggests we open up the generated readme. Apparently now we need to setup a database ourselves. let’s go with dockerized Postgres
| |
Following the readme I check database.yml and to my delight the defaults perfectly match my choices so I can just run
the tooling against my new Postgres server.
| |
Let’s see the schema
| |
No tables yet… Back to readme: start the dev server and open it up in a browser.
| |
Liftoff! This gives me a development server with auto re-compilation.
At this point I was a bit curious about the generated code: tried running tree - 1937 directories, 12700 files….
That’s quite a bit, let’s come back later since I have no good idea where to start.
Generating resources
Let’s try to generate a few more things instead. At this point I’m not following “Getting started” anymore and am trying to emulate a demo I saw on YouTube - rails-like generation of CRUD resources.
The buffalo tool is pretty easy to use and discover commands, after a bit of faffing around with -h I get to
| |
500, apparently i need to run migrations now to create the new tables
| |
Yay I now have CRUD! but no fields xD. Not that I didn’t have to restart or recompile anything, dev server from before picked up changes automatically.
Let’s revert
| |
need to also manually remove the migration in /migrations and clean up routes in actions/app.go (figured this out by trial and error)
At this point I consulted the docs - they are quite nicely structured, I quickly found Generating resources and now know how to generate resources with some actual fields
| |
I added non-string column just for kicks so I can see how it looks when I need to specify the type. And manually run the migrations.
| |
And we have functional crud!
Create
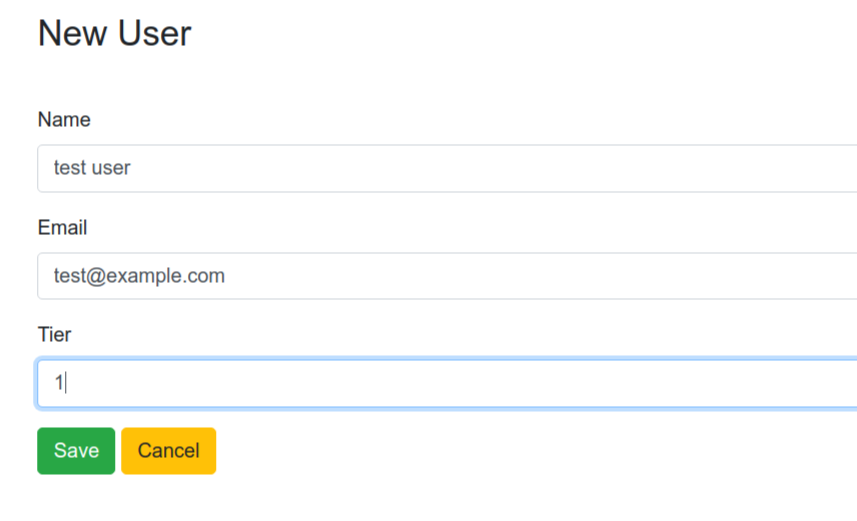
List

Read
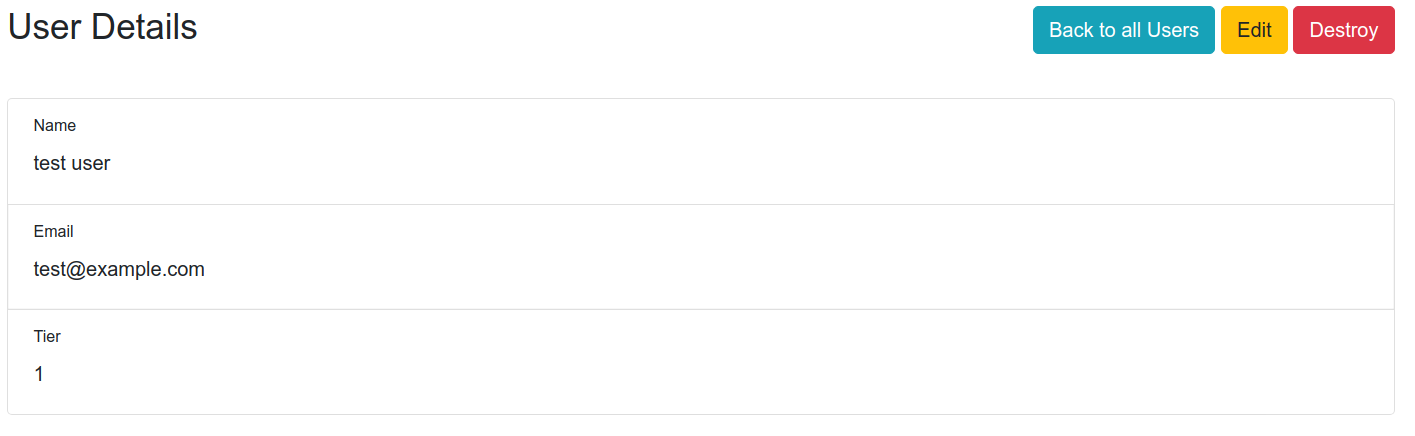
Update
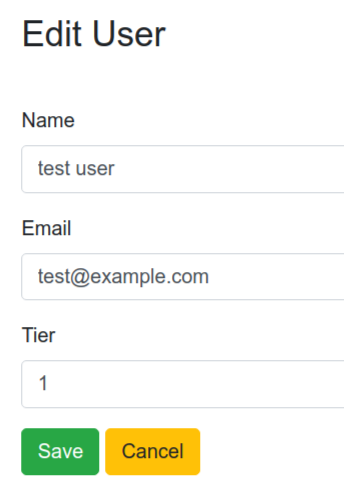
Generated code
Now let’s take a look at the generated code. First for our users. Apparently we generated action, model, and migrations. Let’s start at the rear.
Migrations
Migrations seem quite straightforward (apparently a DSL of some sort to be able to run against different SQL dialects).
up:
| |
down
| |
Model
Apparently we also got test files for bot models and actions, complete with placeholder failing tests. NICE! There is
even buffalo test which does exactly what you expect.
| |
This is in fact the whole model - copied here since it’s quite terse. I very much like the fact a regular Go struct and not some smart active record as I prefer less magic.
Actions
Action itself is actually quite hefty - comes in at 258 lines of code. Here it is in it’s entirety if you want to read through, I’ll just do a brief overview of my reading.
| |
There already is support for pagination, content negotiation (same content can be rendered as html/xml/json), model validation on mutiation. Looks a bit verbose but if you read carefully the code is quite nice, idiomatic Go, with just some patterns repeating for all endpoints.
I do have mixed feelings about it. On one hand it’s nice to have everything spelled out like this - very easy to scaffold and jump in to make customizations. On the other hand I’m afraid this will leave you with hard to maintain copy-pasta over a longer project.
Templates
There is quite a bit going on here. I’ve never used Plush but the syntax looks familiar and the templates look like regular Bootstrap. Basically this follows the same pattern: no surprises, no magic, human-editable code, going for max productivity.
Other generated things
With slightly better understanding i can now try to read through the rest of it. Luckily we also got a generated
.gitignore so I can ask git (git ls-files) for a list of important files.
All in all (after I generated my users resource) I’m looking at 50 files, 1387 lines of code. Not too much to actually read (or skim) through and get a feeling what’s going on. And of course docs cover the important folders.
I’ll just list a few things that have caught my eye
- sane multi-stage dockerfie
- sane gitignore
- go.mod
- main.go - very simple entry point that basically starts the server but leaves you with a place to customize. Again no
magic, you can build this with regular
go build - public assets (complete with favicon & robots.txt)
- assets pipeline (yarn & webpack based, apparently “just works” with the
buffalotool)
Conclusion
I think Buffalo delivers on the promise: you can hit the ground running, yet there is very little magic and it’s built upon other established libraries. But in order to achieve this it is opinionated and possibly restrictive. But this is fine - it’s a trade off you can make: I’ll glacdly pick up Buffalo when I have a need for a quick crud-y site (bye django…) but probably not for starting a new specialised backend/internal service. Then again, if it’s curd-y database-backed thing…
All in all I think it’s a good option to have in one’s toolbox and I’ll probably be using it.
Last modified on 2021-02-07
Previous Attaching your local machine to a Kubernetes clusterNext Trying out Okteto (CLI)