I based prometheus_config/prometheus.yml of of getting started
1
2
3
4
5
6
7
8
global:
scrape_interval: 15s# By default, scrape targets every 15 seconds.scrape_configs:
- job_name: 'prometheus'scrape_interval: 5sstatic_configs:
- targets: ['localhost:9090']
Running docker-compose up -d and we’re off to the races.
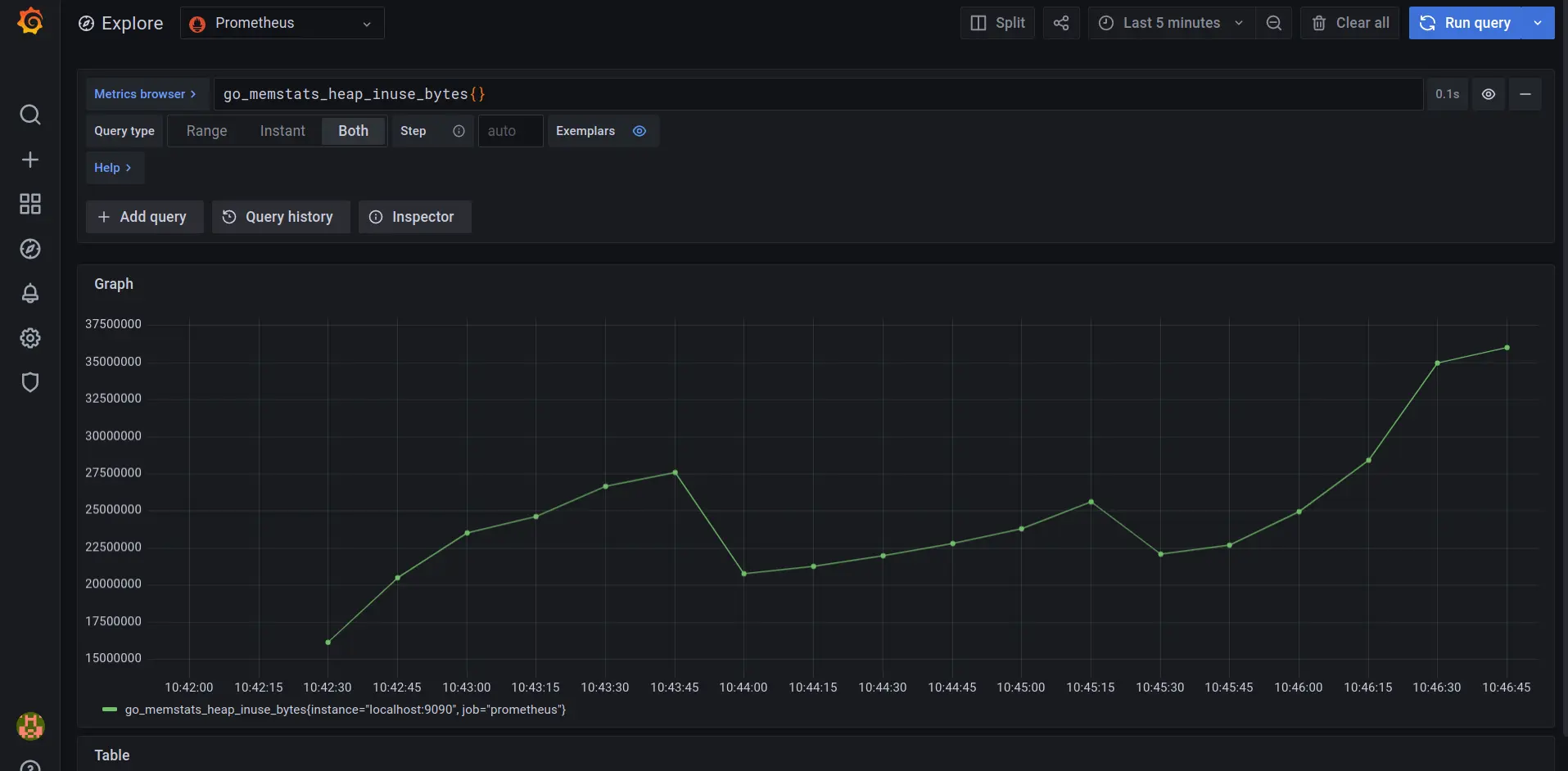
http://localhost:9090 gives the same interface (but now with persistent
storage) but there is now Grafana as well (on port 3000)
And it can easily be configured to point to the Prometheus instance.
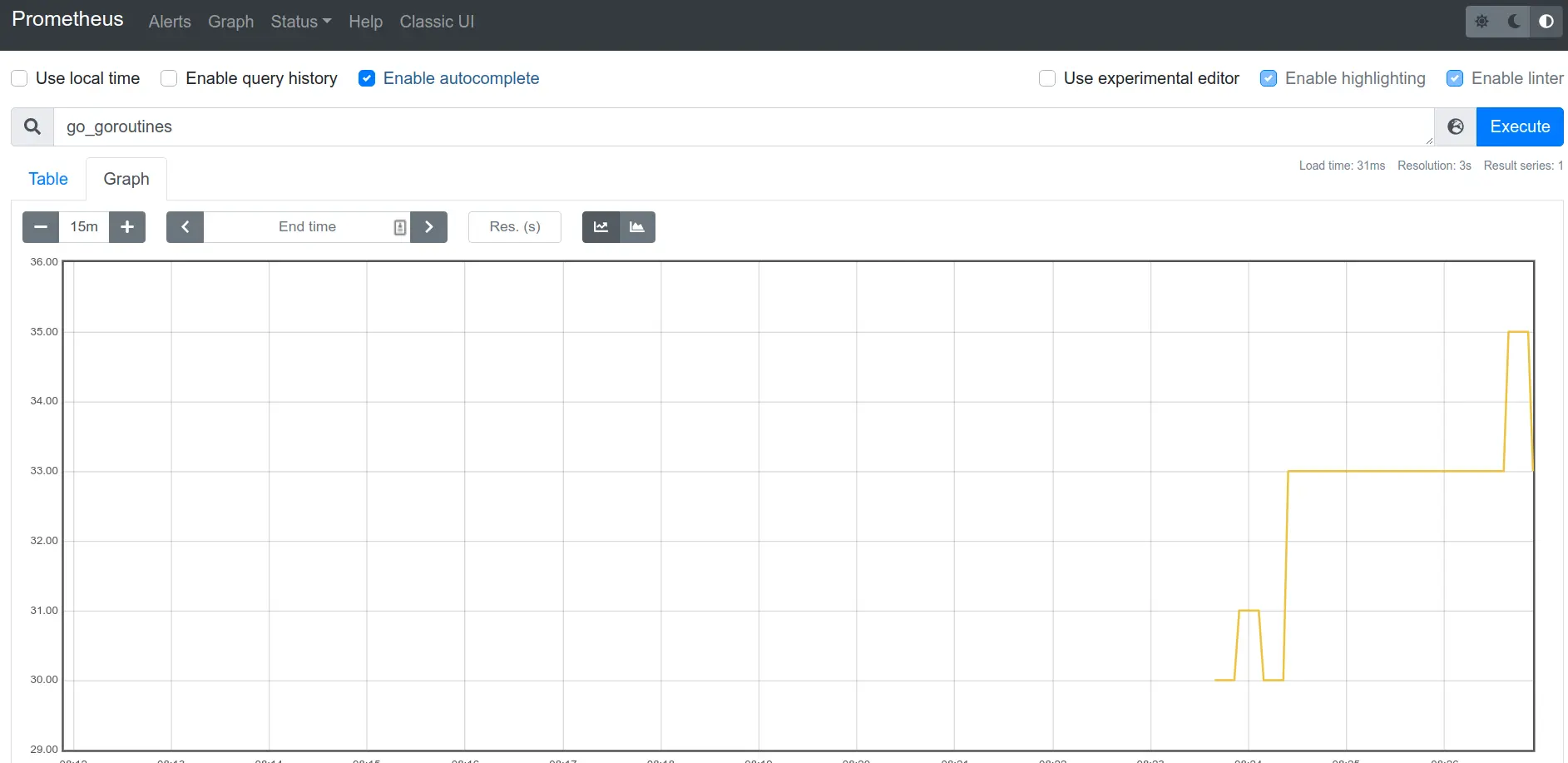
Yaay, metrics in Grafana.
My app
For the next step I want to run my own app and have Prometheus scrape it. To get
started I add gow-based service to my compose
file to have a development friendly environment with auto-recompilation.
1
2
3
4
5
6
7
8
9
app:
image: golang:1.16-alpinevolumes:
- go:/go - ./app:/go/src/appworking_dir: /go/src/appcommand: go run github.com/mitranim/gow run .ports:
- 2112:2112
$ curl -s http://localhost:2112/metrics | head -n5
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.# TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"}0 go_gc_duration_seconds{quantile="0.25"}0 go_gc_duration_seconds{quantile="0.5"}0
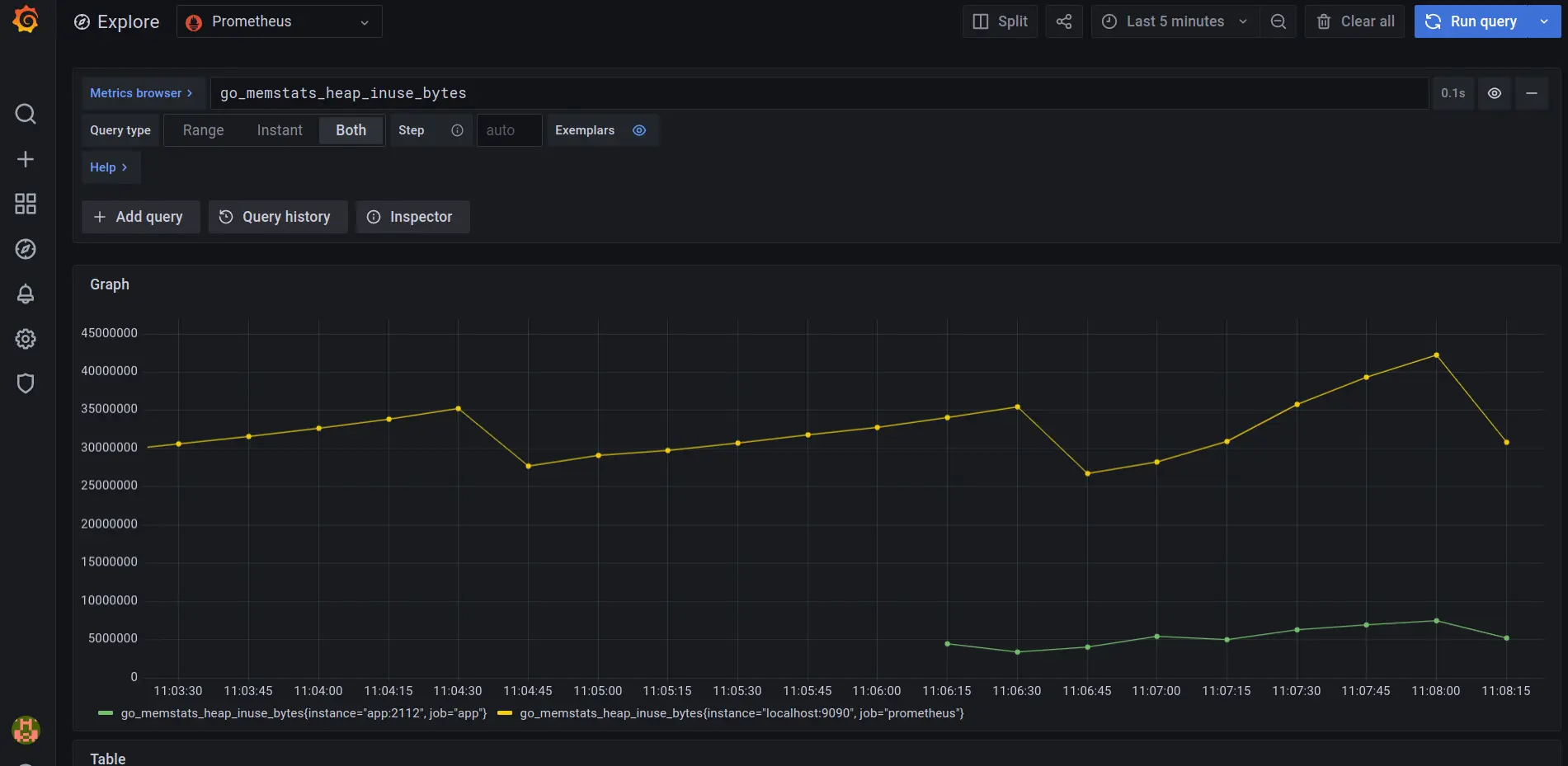
Great. Now I only need to inform Prometheus about the existence of my app.
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm install my-grafana grafana/grafana
NAME: my-grafana
LAST DEPLOYED: Sun Jun 2713:37:332021NAMESPACE: default
STATUS: deployed
REVISION: 1NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace default my-grafana -o jsonpath="{.data.admin-password}"| base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
my-grafana.default.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=my-grafana"-o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 30003. Login with the password from step 1and the username: admin
####################################################################################### WARNING: Persistence is disabled!!! You will lose your data when ########### the Grafana pod is terminated. ######################################################################################
Following instructions (but forwading the sirevice directly)
1
2
kubectl get secret --namespace default my-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
k port-forward service/my-grafana 3000:80
Packaging the app
Time to package up my app
1
2
3
4
5
6
7
8
9
10
FROMgolang:1.16-alpineasbuilderCOPY . /srcWORKDIR/srcRUN go build .FROMalpineWORKDIR/bin/COPY --from=builder /src/app .EXPOSE2112CMD /bin/app
After quite a bit of stumped googling I checked out
values.yaml
of the char I applied and found this explanation
1
2
3
4
5
6
7
8
9
10
11
# Scrape config for service endpoints.## The relabeling allows the actual service scrape endpoint to be configured# via the following annotations:## * `prometheus.io/scrape`: Only scrape services that have a value of `true`# * `prometheus.io/scheme`: If the metrics endpoint is secured then you will need# to set this to `https` & most likely set the `tls_config` of the scrape config.# * `prometheus.io/path`: If the metrics path is not `/metrics` override this.# * `prometheus.io/port`: If the metrics are exposed on a different port to the# service then set this appropriately.
So I figured to add prometheus.io/scrape to my manifests. But where? Service
or pod spec? I Prometheus should scrape pods in my case since I want to get
counter values per-pod.
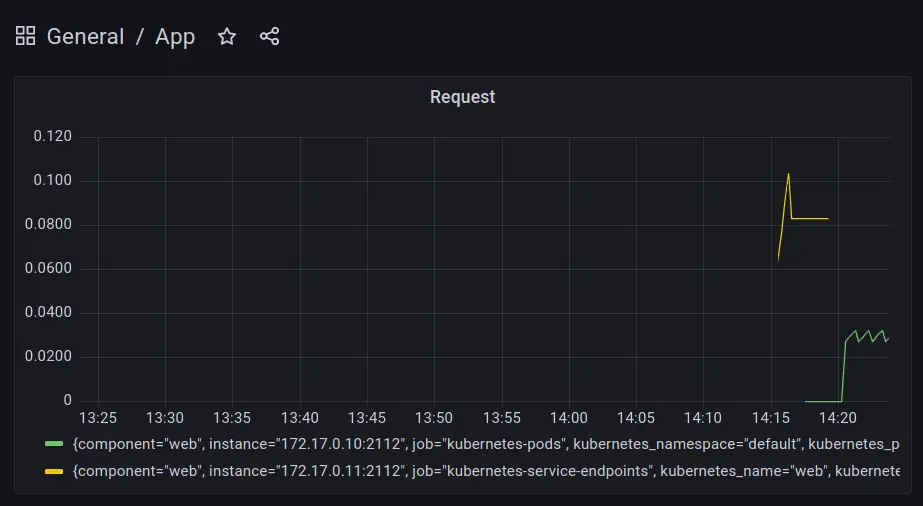
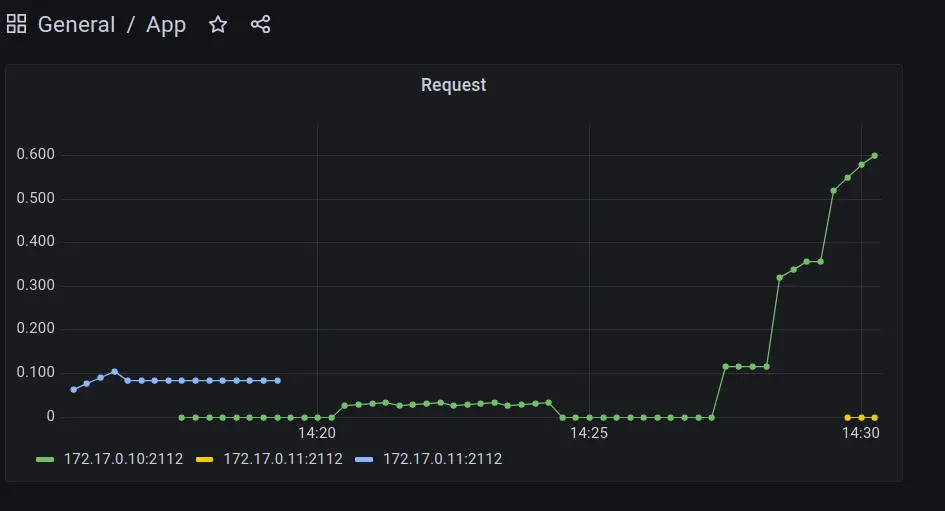
My pod is picked up on localhost:9090/targets, great success.
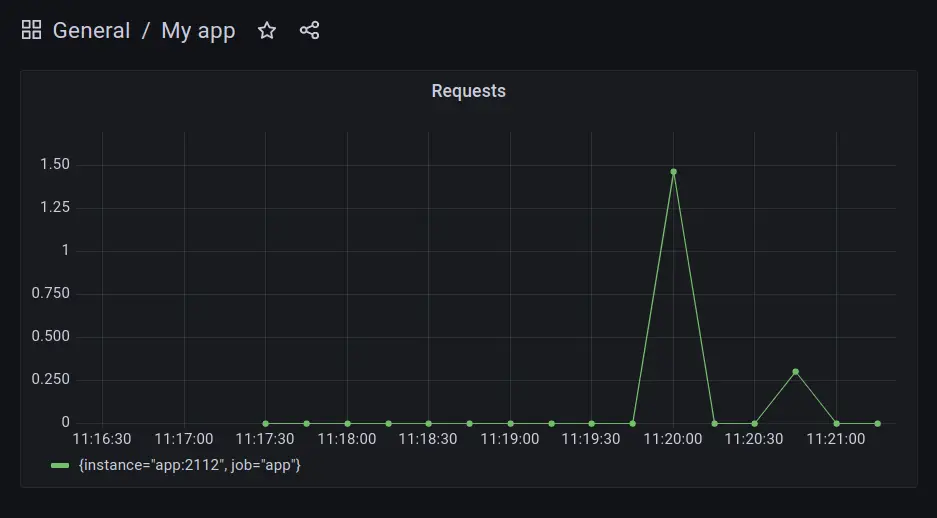
Naturally metrics also show up in Grafana
Killing pods/scaling deployment is nicely visible in metrics now.
Conclusion
Setting up Prometheus was actually quite straightforward. So is configuring the
actual scraping. Application codebase doesn’t need to know anything about my
infrastructure, no configuration needed - it simply exposes a /metrics/
endpoint. Then scraping is enabled in my deployment manifest.
For me the part that actually needs some getting used to is the query language,
but I think the infrastructure niceties are well worth it.